


















VERDELING VAN DE DATA
![]() Description
Description
De verdeling van de data wordt getoetst door de verdeling vanuit de meting te toetsen aan verdelingen zoals die idealiter zouden lopen. Hoe beter de verdeling past, hoe groter de match met de verdeling en de kans dat je mag aannemen dat de verdeling het voorspelbare patroon volgt.
Vraagstelling: heeft de procesprestatie een (normaal) verdeling?
- De Normal Probability Plot geeft inzicht of het proces normaal verdeeld is.
- Als de procesprestatie niet normaal verdeeld is, kan er worden getest of de data een andere verdeling passen door een Individual Distribution Identification test uit te voeren.
- De uitkomst van de Probability Plots worden weergegeven in een getal: de P-waarde.
![]() When
When
In de fasen Analyseren probleem.
![]() Goals
Goals
Het wordt gebruikt om te toetsen of de data voorspelbaar zijn. Als een proces geen herkende verdeling heeft, is de conclusie dat de uitkomsten uit de meting min- der betrouwbaar zijn. Het is dan niet met zekerheid te zeggen dat een volgende meting dezelfde, vergelijkbare uitkomsten zal hebben. Dat is niet direct een streep door de rekening voor de meting, maar geeft wel aan de procesbegeleider aan dat hij de meetresultaten niet als onfeilbaar feit mag presenteren.
![]() Steps
Steps
- Verzamel betrouwbare en representatieve data over het proces.
- Gebruik de Minitab of Excel om een Probability Plot en/of Individual Distibution Identification te maken.
![]() Examples
Examples
Hier volgt een voorbeeld van een regelkaart van de bewerkingstijden van een proces. De Individual Distribution Identification geeft in verschillende grafieken de uit- komsten van de Normal, Exponentiële, Weibull en Lognormal test. Overigens is er een toets mogelijk om veertien verschillende verdelingen te genereren, maar deze komen het meest voor.
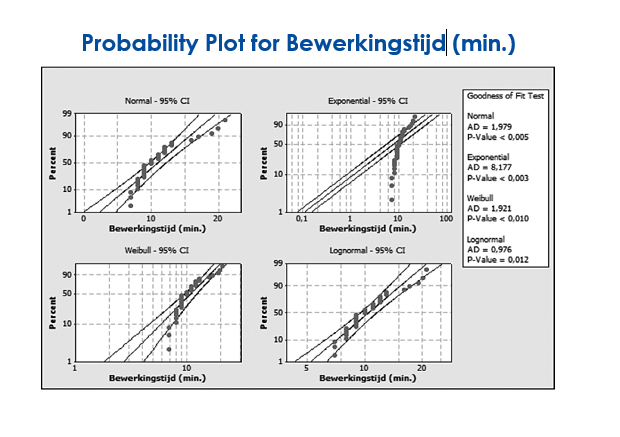
Figuur: Probability Plot
Om te beslissen welke verdeling er geldt, gebruiken we de volgende beslisboom:
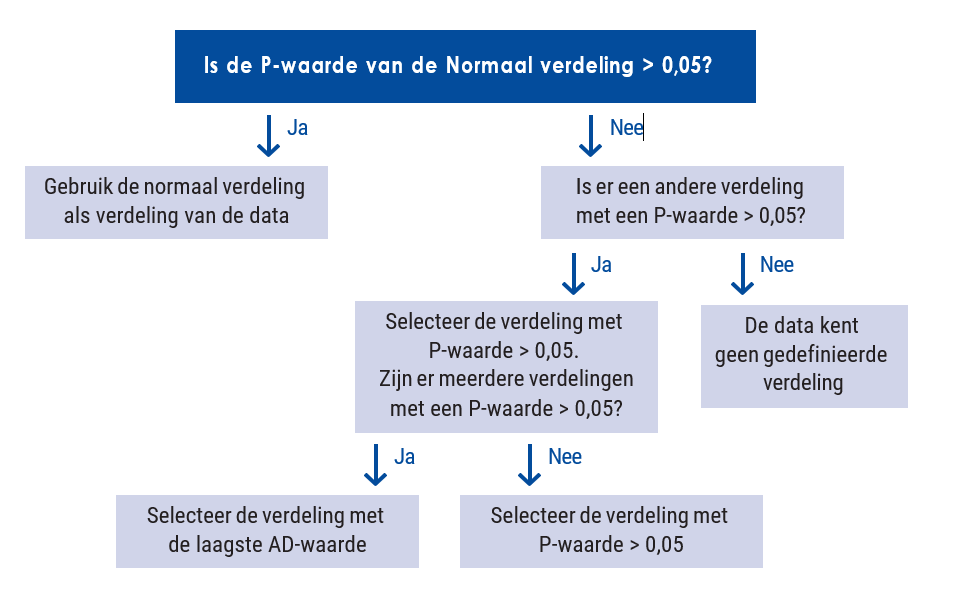
Figuur: Beslisboom
Indien er geen gedefinieerde verdeling van de data wordt geconstateerd, dan kan dat verschillende oorzaken hebben:
- Incidenten in het proces waardoor data uitschieters vertonen.
- De data betreft twee (of meer)
– Verschillende processen;
– Verschillende producten;
– Verschillende complexiteit van uitvoering.
Als er een complexiteit van uitvoering wordt gesignaleerd, kan het raadzaam zijn de verschillende processen apart te analyseren.
Als er geen gedefinieerde verdeling is, zeggen gemiddelde en standaarddeviatie niets over het proces. We gebruiken dan alternatieve waarden als mediaan en kwartielen. We werken dan bijvoorbeeld met een boxplot om de verdeling van het proces aan te geven.
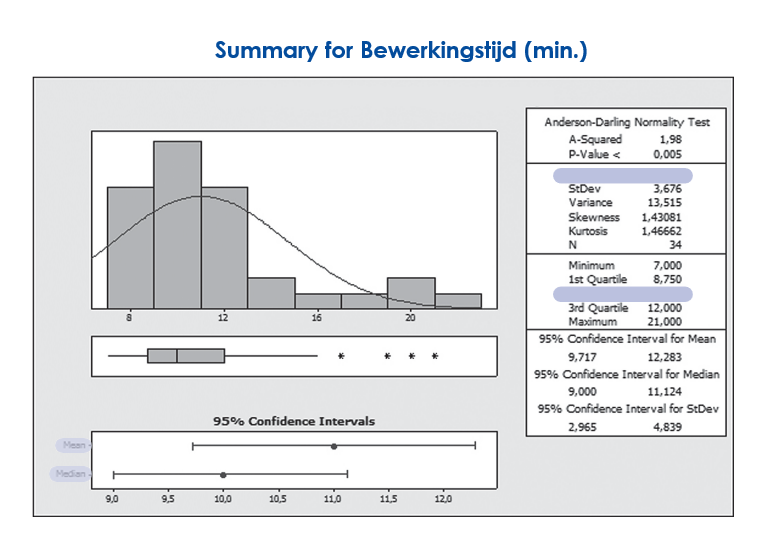
Figuur: Samenvatting bewerkingstijd
![]() Tips:
Tips:
- Verwacht geen normaal verdeelde data. De meeste processen (in serviceorganisaties) kennen niet zo’n voorspelbaar patroon.
- Als er geen gedefinieerde verdeling is, komt dat vaak doordat er verschillende invloedfactoren zijn die maken dat het proces verschillend loopt. Het lukt echter niet altijd om achter deze invloedfactoren te komen, omdat er veel kleine factoren zijn die in combinatie het proces beïnvloeden.
